Innego końca sieci nie będzie. Teoria martwego internetu
Heroldem przemian technologicznych i społecznych, jakie czekają nas w XXI wieku, jest powolna śmierć internetu. Spokojnie, nie chodzi mi o dosłownie rozumianą śmierć, tylko raczej o powolne wysysanie życia z tego niegdyś pełnego wigoru miejsca.
Adam Bełda
23
Świat się zmienia. Coraz szybciej. Skok cywilizacyjny, jaki ludzkość wykonała w ciągu ostatnich stu lat, jest tak naprawdę trudny do wyobrażenia. Spróbujmy przenieść się w lata 20. zeszłego wieku, czasy, w których kluczowe dla współczesności osiągnięcia technologii albo nie istnieją, albo dopiero raczkują. Samochody są nowinką technologiczną, dostępną w masowej produkcji od zaledwie kilkunastu lat. Silnik odrzutowy, a co za tym idzie – samolot w postaci, jaką znamy dzisiaj, – jeszcze nie został wynaleziony. O komputerach oczywiście można tylko pomarzyć. Możemy za to być świadkami narodzin Marilyn Monroe, pogawędzić z Johnem R.R. Tolkienem czy Howardem Philipsem Lovecraftem oraz uczestniczyć w zbiorowym przepracowywaniu traumy wielkiej wojny, mając nadzieję, że nic podobnego – a już na pewno nie wojna większa i bardziej okrutna – się już nie wydarzy.
Treści premium wymagają więcej czasu i wysiłku i mogą powstawać głównie dzięki Waszemu wsparciu jako czytelników GRYOnline.pl. Jeśli chcecie czytać podobnego rodzaju treści, rozważcie kupno abonamentu!
Prawo przyspieszających zwrotów
Ważny głos w polemice, czy rozwój ludzkości faktycznie przyspiesza, czy jest to tylko złudzenie związane z uproszczonym postrzeganiem wydarzeń sprzed wieków, stanowi sformułowane przez Raymonda Kurzweila prawo przyspieszających zwrotów. Zakłada ono, że w istocie proces ten postępuje w tempie wykładniczym, a więc coraz szybciej. Miałoby to być spowodowane tym, iż następujące po sobie odkrycia kumulują się i stanowią bazę dla jeszcze szybszego dokonywania kolejnych. Kiedy dana technologia osiągnie swój naturalny limit, pojawia się nowy paradygmat (np. przejście z komputerów lampowych na tranzystorowe, a później na oparte na układach scalonych) pozwalający na jeszcze większą dynamikę jej ewolucji. Zainteresowanych tą koncepcją odsyłam do nieco już nieaktualnej, ale wciąż niesamowicie stymulującej intelektualnie książki Nadchodzi osobliwość czy jej duchowej następczyni z tego roku Osobliwość coraz bliżej.
Dzisiaj wydaje się to odległą przeszłością, ale przecież sto lat to nie jest długi okres w kontekście historii świata. Żyją jeszcze ludzie, którzy pamiętają te czasy – albo mogliby je pamiętać, gdyby wiek nie zatarł tych wspomnień w ich umysłach. Można więc całkiem bezpiecznie założyć, że i obecnie w ciągu okresu możliwego do przeżycia przez człowieka Ziemia zmieni się nie do poznania. Jednej z tych zmian właśnie jesteśmy świadkami.
Oto koń trupio blady, a imię siedzącego na nim Śmierć, i Otchłań mu towarzyszyła
Heroldem przemian technologicznych i społecznych, jakie czekają nas w XXI wieku, jest powolna śmierć internetu. Ktoś mógłby powiedzieć: „To bzdura! Internet rozwija się jak nigdy, gdzież mu tam do emerytury, a ty posyłasz go do grobu!”. Spokojnie, nie chodzi mi o dosłownie rozumianą śmierć, tylko raczej o powolne wysysanie życia z tego niegdyś pełnego wigoru miejsca.

Jak pewnie nietrudno się domyślić, jestem zdania, że jako ludzkość stoimy u progu być może największej rewolucji, jaka kiedykolwiek miała miejsce. Porównać mogę ją z popularyzacją smartfonów, ale potencjał, jaki w niej drzemie, oceniam na znacznie większy. A o co konkretnie mi chodzi? O powstanie i upowszechnienie generatywnej sztucznej inteligencji, która powoli staje się na tyle zaawansowana, że możliwe jest zastosowanie jej na dużą skalę w zadaniach komercyjnych. Od dość dawna wiemy, że jeśli komputer jest w stanie zrobić z grubsza to samo co człowiek, to pewnie zrobi to szybciej – przekonały się o tym chociażby osoby (co ciekawe, ze względu na ówczesne uwarunkowania kulturalne – głównie kobiety) wykonujące obliczenia na potrzeby badań naukowych czy operacji wojskowych. Dodatkowo maszyna jest tańsza w utrzymaniu niż pracownik, nie męczy się i można ją łatwo zduplikować.
Taktowanie mózgu?
Podczas gdy obecnie dostępne dla masowego użytkownika procesory są w stanie wykonywać miliardy operacji w ciągu sekundy, ludzka komórka nerwowa potrafi przesłać dalej sygnał w tym samym czasie jedynie kilkaset razy. Ograniczenie to wynika głównie z mechanizmu przewodzenia – o ile iglica potencjału czynnościowego może trwać milisekundę, tak okres refrakcji, czyli następującej potem niewrażliwości na bodźce, już kolejne kilka do kilkudziesięciu. Oczywiście nie da się przełożyć tego jeden do jednego na wydajność obu systemów, gdyż każda komórka ludzkiego mózgu jest niezależną jednostką obliczeniową, może więc pracować w tym samym czasie, zaś współczesne procesory wyposażone są w zaledwie kilkanaście rdzeni, co pozwala im na równoczesną obsługę nieco ponad dwudziestu wątków. Pod tym względem funkcjonowanie mózgu lepiej byłoby porównać do pracy karty graficznej, nie bez powodu więc to często ten komponent uczestniczy w obliczeniach potrzebnych do działania sztucznej inteligencji.
Do tej pory wykorzystywaliśmy komputery tylko w zadaniach, do których zastosować można było konkretne, opracowane wcześniej przez programistów algorytmy. Owszem, maszyna mogła dokonać tysięcy obliczeń w czasie krótszym niż mgnienie oka, jednakże tylko wówczas, gdy dało się jej dokładne instrukcje, precyzyjnie określające krok po kroku, jak wykonać zadanie. Jeśli program był niedokończony albo zawierał błędy – cóż, trzeba było go przebudować. Albo wydać 10 grudnia 2020 roku i liczyć, że nic się nie stanie.
Klasycznie napisany program komputerowy nie jest w stanie dynamicznie reagować na zmieniające się warunki. Nie jest więc w stanie symulować kreatywności ani... głupoty. Stworzenie generatora shitstormów w mediach społecznościowych byłoby pewnie możliwe bez odwoływania się do najnowocześniejszych technologii, ale byłby on na tyle niskiej jakości, że prawdopodobnie nie udałoby się nikogo oszukać. Syntetyczny trolling zawsze byłby zlokalizowany, rozpoznany i zignorowany. Dzisiaj jednak mamy dostęp do narzędzi, które w ułamku sekundy potrafią wygenerować zarówno chwytliwe hasło marketingowe czy obrazek Jezusa zbudowanego z krewetek, jak i paszkwil na przeciwnika politycznego.
Test Turinga
Wybitny matematyk i pionier informatyki Alan Turing zaproponował w 1950 roku test mający symbolicznie wytypować prawdziwie „myślące” sztuczne inteligencje. Miał on polegać na tekstowej konwersacji sędziego z grupą rozmówców, wśród których byliby zarówno ludzie, jak i programy komputerowe. Jeśli maszynie udałoby się oszukać sędziego, by ten pomyślał, że rozmawia z prawdziwym człowiekiem, byłoby to uznane za sukces. Odpowiednia proporcja podejść udanych do nieudanych świadczyć miała o zaliczeniu testu. Doniesienia o tym, że takie sztuczne inteligencje udało się stworzyć, pojawiały się już w drugiej dekadzie obecnego wieku, a w ostatnim czasie znacznie przybrały na sile. Obecnie możemy już bez większych kontrowersji uznać, że istnieją modele językowe, które przeszły test Turinga, w tym np. popularny ChatGPT. Ciekawe jest to, że w powieściach science fiction tworzonych w poprzednim stuleciu często pojawiało się określenie „maszyny turingowe”, traktowane jako synonim przełomu i czegoś, co wymyka się dotychczasowym schematom. A kiedy prawdziwe maszyny turingowe są wśród nas, my po prostu wzruszamy ramionami i pytamy ich, jakie pyszne danie przygotowałyby pani Krysi z papryki chili, bitej śmietany i karmy dla kota...
Tak, zostaliśmy zdetronizowani. Już nawet do najbardziej ludzkiego z ludzkich zajęć, ukoronowania dziesięciu tysięcy lat rozwoju cywilizacji, czyli pisania bzdur w internecie, człowiek jest zbędny.
Martwy internet
Bezpośrednią inspiracją do napisania tego artykułu był viralowy screen – użytkownik Reddita chciał znaleźć informacje na temat Johna Wicka 5, ale po wpisaniu w Google’a tytułu filmu ujrzał głównie fake newsy oraz treść wygenerowaną przez boty. Nie udało mi się uzyskać takiego wyniku – może to wina profilowania, a więc innych sugestii wyświetlanych konkretnym użytkownikom, albo różnic lokalnych, a może wpis na temat fałszywych informacji podawanych przez wyszukiwarki sam został spreparowany, by zebrać więcej lajków (trudno powiedzieć, czy taki stan rzeczy zmniejszałby, czy zwiększałby wiarygodność tezy autora). Nie ulega jednak wątpliwości, że sytuacja, w której szukając artykułów na dany temat, zostaniemy zalani morzem clickbaitowych fałszywek, jest w 2025 roku wysoce prawdopodobna.
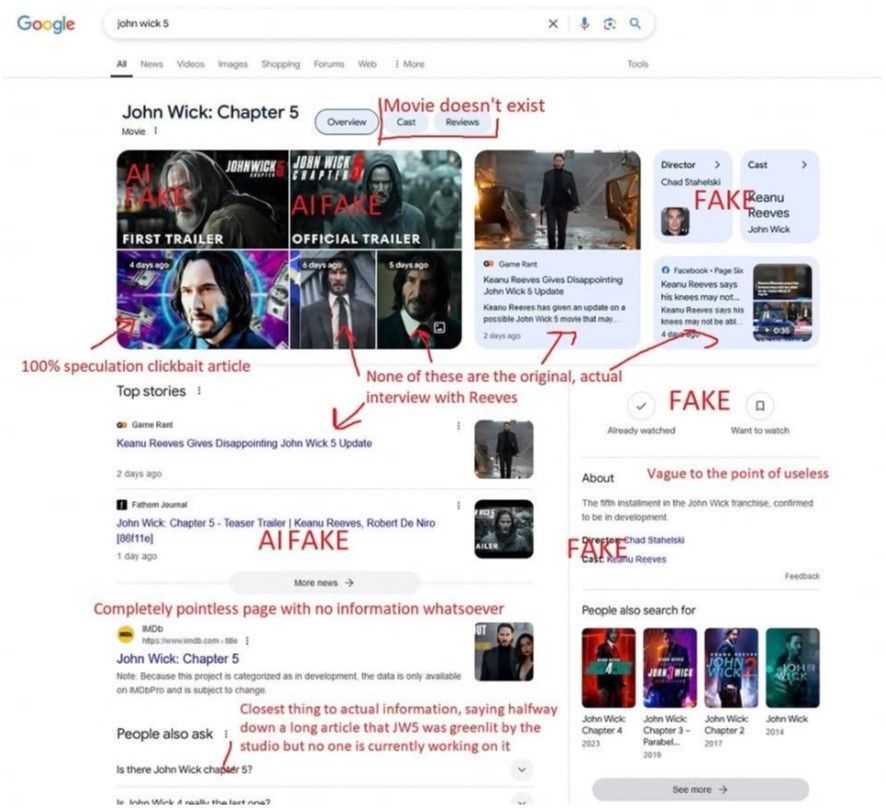
Jako że stwierdzenie, iż większość internetu to stek niskiej jakości bzdur, wydaje się zupełnie niekontrowersyjne, a obecna technologia umożliwia generowanie takich treści bez udziału człowieka, można zadać sobie pytanie, czy faktycznie nie jest tak, że to komputery przejęły palmę pierwszeństwa w wytwarzaniu contentu. O to właśnie chodzi z „martwym internetem” – że aktywność żywych istot (a więc ludzi, reptilian i hodowanych w podziemiach lóż masońskich okropieństw) stanowi w istocie mniejszość całego ruchu w sieci.
Trudno powiedzieć, kto pierwszy postawił taką tezę. Jej początek datować należy prawdopodobnie na rok 2019, zyskiwała wtedy popularność w anglojęzycznych serwisach, takich jak Reddit czy 4chan, były to jednak dość luźne rozważania na temat tego, w jakim stopniu aktywność botów wpływa na konstrukcję internetu. Na twarde sformułowanie postulatów trzeba było poczekać do roku 2021, kiedy to na forum Agora Road’s Macintosh Cafe użytkownik o nicku IlluminatiPirate założył temat zatytułowany „Dead Internet Theory: Most Of The Internet Is Fake”. Oryginalnie śmierć internetu datowana była na przełom 2016 i 2017 roku. To wtedy bezwartościowa i przede wszystkim nietworzona przez żywe istoty treść miała zacząć dominować nad tym, co publikowali ludzie z krwi i kości. Miało to oczywiście mieć związek z zakusami korporacji medialnych oraz technologicznych, dążących do zyskania kontroli nad społeczeństwem. Ludzie nieświadomi, że pozbawieni są dostępu do pluralistycznej natury internetu z poprzednich lat, mieli być karmieni jedyną słuszną wizją świata, która byłaby zbieżna z interesami ich nowych hegemonów.
Tak, to była jedna z tego rodzaju teorii, które w zasadzie są prawdopodobne, ale jednak spiskowe z powodu skali. Oczywiste jest bowiem, że kontrola, jaką nad naszymi umysłami ma branża technologiczna, wydaje się niepokojąco duża, a koncerny dążą do tego, żeby była jeszcze większa. Dowodem (co prawda anegdotycznym, ale myślę, że odnoszącym się do doświadczenia większości czytelników) niech będzie fakt, że zanim usiadłem dzisiaj do pisania tego artykułu, zmarnowałem dwie godziny życia na scrollowanie YouTube’a. Czy miałem to w planach? Jasne, że nie, ale socjotechnika stosowana przez Google’a jest tak dobra, iż moje świadome cele musiały poczekać. Z drugiej jednak strony, nie wydaje się, żeby już 8–9 lat temu technologia pozwalała na tak realistyczne udawanie treści wytwarzanej przez człowieka. Zarówno ChatGPT, jak i Midjourney, które to były swoistym przełomem w generowaniu treści, udostępnione zostały szerszej publice dopiero w 2022 roku. Wcześniejsze masowo dostępne narzędzia generatywnej sztucznej inteligencji nie funkcjonowały na tyle dobrze, aby móc stanowić realną konkurencję dla twórczości ludzkiej. Standardem w rozpowszechnianiu fake newsów czy spamu były albo farmy trolli – a więc grupy ludzi wyspecjalizowanych w zalewaniu portali konkretną treścią – albo boty, które postowały w różnych miejscach wcześniej przygotowane teksty czy obrazki. Oczywiście możliwe, że już przed 2022 rokiem wczesne wersje bardziej zaawansowanych narzędzi udostępniane były odpowiednio bogatym i wpływowym firmom, ale nie ma dowodów na to, by odbywało się to na masową skalę.
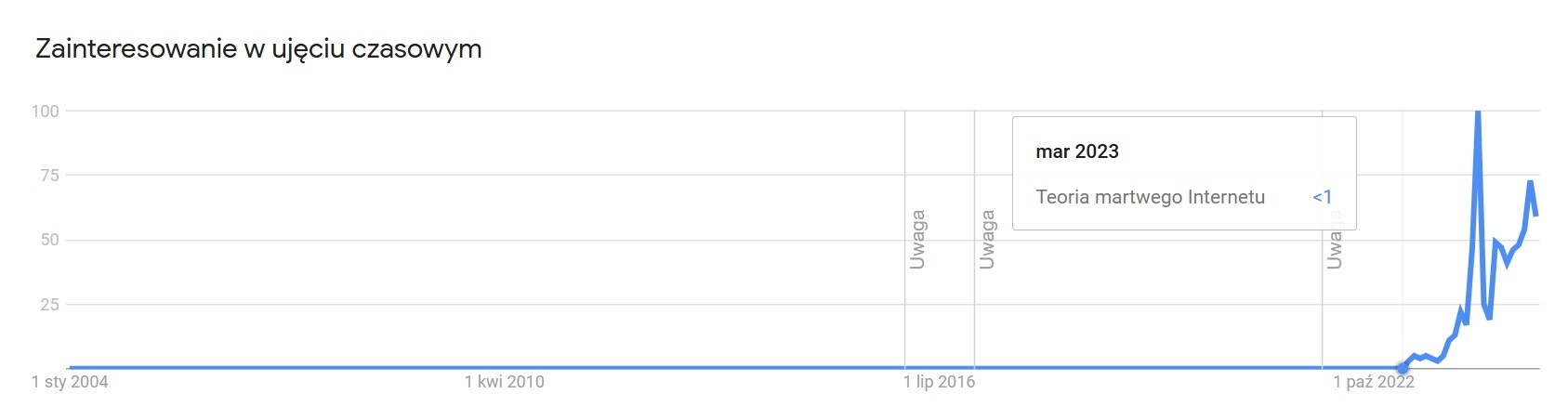
Czy więc warto wierzyć w teorię martwego internetu? Moim zdaniem, o ile jej „kanoniczna”, sięgająca niemal dekadę wstecz, wersja jest swego rodzaju przesadą, tak jeśli odnieść ją do dzisiejszego stanu rzeczy, istnieją mocne dowody na to, że jest w niej co najmniej ziarno prawy. Według Originality.ai ponad 40% przebadanych treści publikowanych na Facebooku jest generowanych wyłącznie przez AI. Wnioski te wysnuto na podstawie analizy 8855 postów z okresu od listopada 2018 do listopada 2024 roku. Co prawda metodologia tego badania była krytykowana – wskazywano na przykład na treści tworzone przez ludzi mylnie oznaczone jako dzieło AI – jednakże nawet przy założeniu bardzo dużego, rzędu 50%, błędu i tak mamy do czynienia z niepokojąco dużą częścią internetu dającą się zakwalifikować jako martwa.
Jednak zaczęło się w 2016?
Wśród argumentów podawanych przez zwolenników oryginalnej wersji teorii martwego internetu często można znaleźć raport firmy Interva z 2016 roku o udziale botów w ruchu w sieci. Został on wówczas oszacowany na ponad 50%! Czyżby faktycznie internet był martwy już wtedy? Cóż, w pewnym sensie tak – w końcu za większość generowanego ruchu odpowiedzialne były byty czysto cyfrowe. Diabeł tkwi jednak w szczegółach – raport nie dotyczył generowania przez boty treści, tylko samych odwiedzin. Obejmował więc głównie algorytmy dotyczące katalogowania sieci przez wyszukiwarki, analizy marketingowej czy monitorujące różne procesy. Nie jest to więc dowód na rzecz teorii martwego internetu sensu stricto. Nie zmienia to jednak faktu, że jeśli tworzysz właśnie stronę internetową, większości odwiedzających ją „osób” prawdopodobnie nie będą stanowić ludzie.
Zresztą nikt tak naprawdę nie kryje się z tym, że boty są istotnym problemem współczesnego internetu. Szczególnie widoczne było to po przejęciu przez Elona Muska Twittera, kiedy to po wprowadzeniu przez nowego właściciela zmian na niegdyś ćwierkającym portalu (monetyzacja treści oraz zwolnienie dużej części moderacji) doszło tam do istnego wysypu kont nieprowadzonych przez ludzi. Według różnych oszacowań martwych miało być od 5% do 13% wszystkich kont zarejestrowanych w serwisie. Wydaje się to niewielkim odsetkiem, jeśli jednak weźmiemy pod uwagę, że bot może postować bez przerwy przez dowolnie długi czas, okaże się, że nawet drobny procent automatycznych użytkowników jest w stanie stworzyć istotną część publikowanej treści.
Aktywność sztucznej inteligencji jest już zresztą widoczna gołym okiem. Portale społecznościowe wprost zalewane są przez komputerowo generowane zdjęcia mające wzbudzać współczucie czy odnoszące się do uczuć religijnych. Prawdopodobnie każdy widział już obrazki z cyklu „Zrobiłem samolot z plastikowych butelek i nikt mi nie pogratulował”, „Jeśli nie gardzisz mną, bo jestem rolnikiem, to przywitaj się ze mną” czy „Dziś są moje 99 urodziny, ale nikt nie złożył mi życzeń”. Może się wydawać, że tego rodzaju obrazki są zbyt oczywiste, aby ktoś mógł się na to nabrać, a jednak potrafią uzyskać dziesiątki tysięcy polubień i wielokrotnie więcej wyświetleń. Znaczenie ma tutaj efekt skali – po pierwsze, bot może wyprodukować dowolną liczbę takich grafik w ciągu dnia, więc któraś na pewno przyciągnie uwagę, a po drugie, jeśli takich automatów jest więcej, mogą one komentować sobie nawzajem i udostępniać swoje posty, a przez to zwiększać ich zasięg. Tak, podbijanie zasięgu może w dzisiejszych czasach odbywać się w ogóle bez udziału człowieka.

Tego rodzaju akcje mające na celu „farmienie” lajków, najczęściej z zamiarem późniejszej sprzedaży profilu o dużych zasięgach, są wyjątkowo proste do przeprowadzenia. Ustawia się model językowy tak, aby generował schematyczne, budzące pozytywne skojarzenia albo wzbudzające współczucie prompty, a moduł odpowiedzialny za grafikę generował na ich podstawie obrazki. Publikację takich materiałów również można zautomatyzować, co pozwala na dosłowne zalanie internetu masą śmieciowego contentu, przyciągającego uwagę pewnych typów odbiorców. Profile religijne – również niesamowicie popularne, jeśli chodzi o postowanie obrazków stworzonych przez sztuczną inteligencję – mają jeszcze prostsze zadanie. Wystarczy, że będą produkować bliźniaczo do siebie podobne obrazki z Jezusem (albo inną centralną postacią religii, uwagę wyznawców której chce się przykuć) oraz jakimś sztampowym tekstem.

Zjawisko to, jak wszystko w internecie, doczekało się również swoich parodii – jednych bardziej, innych mniej zabawnych. Moim zdaniem ironiczne jest to, że przez łatwość tworzenia takich treści bardzo szybko stały się one nudne, powtarzalne i nieśmieszne. Były generowane w tak samo bezmyślny sposób jak oryginały – bez polotu i pomysłu, co doskonale obrazuje stwierdzenie Nietzschego, że jeśli zbyt długo patrzysz w otchłań, otchłań zacznie wpatrywać się w ciebie. Jednakże wart uwagi jest przygotowany dla żartu przez portal donald.pl chałkoń. Obrazek kobiety, która upiekła konia z chałki, szybko stał się memem i swoistym fenomenem w polskiej części internetu (co spowodowało pojawianie się tysięcy słabych, tworzonych przez sztuczną inteligencję podróbek, a potem podróbek podróbek...). Jako że autorzy nie byli anonimowymi osobami, odnieśli się do niespodziewanej popularności swojego tworu w serii wiadomości w swoich mediach społecznościowych i przyznali, że wśród osób, które udostępniały grafikę, było wiele takich, które uwierzyły w jej autentyczność.

Sztuczna inteligencja nie jest oczywiście bezbłędna. I czasami coś idzie nie tak w wyjątkowo spektakularny sposób. Poza grafikami czy tekstami, które są po prostu nieudane i mocno niskiej jakości, występują też takie, które jawnie informują, że mamy do czynienia z mistyfikacją. Boty niejednokrotnie powiadamiają użytkownika o problemach technicznych, na przykład, że klucz do API (identyfikator, który pozwala na używanie programu w ramach innych aplikacji) jest nieaktualny, ale jeśli w procesie publikacji nie ma nikogo żywego, taki komunikat trafia do internetu zamiast żądanej treści. Brak moderacji może też sprzyjać sytuacjom, w których skrypt postujący wiadomość nie usunie promptu podanego sztucznej inteligencji, przez co czytelnicy będą mogli zapoznać się także z treścią pytania. Takie sytuacje są istotne zwłaszcza wtedy, kiedy mamy do czynienia z martwym contentem wyjątkowo wysokiej jakości. Takim, co do którego nie spodziewalibyśmy się, że został stworzony przez maszynę. A wraz z rozwojem technologii tego rodzaju sprytnie udających człowieka botów będzie coraz więcej.
Chiński pokój
Doskonałym przykładem tego, jak odróżnić myślącego i rozumiejącego rozmówcę od sztucznej inteligencji, jest scena z książki Petera Wattsa Ślepowidzenie. Powieść opowiada o załodze statku kosmicznego, która ma za zadanie skontaktować się z obcymi istotami. Okazuje się jednak, że nie są one świadomymi bytami, a jedynie sprawnie udającymi inteligencję automatami. Jedna z bohaterek rozpoznaje to po dziwnym sposobie, w jaki kosmici prowadzą z nią rozmowę. Niby odpowiadają na zadawane pytania, ale w sposób zaskakująco podobny do tego, w jaki mógłby odpowiedzieć ChatGPT. Przykładowo, po poruszeniu tematyki rodowodu ich gatunku, wchodzą w dygresje na temat ewolucji i drzew genealogicznych, bo nie rozumieją, co w tej rozmowie jest dla świadomych bytów istotne. Bohaterka uzyskuje pewność, że ma do czynienia z organicznym botem, kiedy bez zapowiedzi wysyła agresywną, wulgarną wiadomość, a zamiast reakcji otrzymuje odpowiedź złożoną z tej samej pozbawionej treści waty słownej.
Konsekwencje
Ktoś mógłby spytać – w czym problem? Internet od zarania składał się w dużej mierze z głupich obrazków, teraz jest ich po prostu więcej i są jeszcze głupsze. Takie postawienie sprawy już dzisiaj wydaje się nie brać pod uwagę pewnych istotnych zjawisk, na które wpływ ma wysyp komputerowo generowanej treści. A pamiętać należy, że obecny poziom tego, z czym mamy do czynienia, jest prawdopodobnie jedynie ułamkiem tego, czego możemy się spodziewać w najbliższych latach. Sztuczne inteligencje będą coraz powszechniejsze i coraz potężniejsze, a jednocześnie – wraz z trafieniem technologii pod strzechy – coraz mniej bezpieczne w użytkowaniu.
Made in China
Hitem internetu okazał się niedawno model językowy DeepSeek. Sztuczna inteligencja chińskiego startupu miała być potężniejsza, a jednocześnie wielokrotnie tańsza niż popularny ChatGPT. Niestety, oszczędności szukano nie w bardziej optymalnym zarządzaniu projektem czy lepszych rozwiązaniach technologicznych, tylko... w dość spektakularny sposób zaniedbano kontrolę bezpieczeństwa użytkowania aplikacji. Analitycy firmy Wiz Research odkryli, iż dwie bazy danych zawierające wrażliwe dane dotyczące aplikacji były publicznie dostępne i w ogóle niezabezpieczone. Oznacza to, że każdy dysponujący podstawowymi umiejętnościami użytkownik internetu przy odrobinie zachodu mógł zyskać do nich dostęp. Wśród wyciekłych danych znajdowały się historie czatów z użytkownikami czy informacje na temat infrastruktury samego DeepSeek.
Świat stoi obecnie u progu kryzysu energetycznego. Poszukiwanie źródeł energii, które byłyby bezpieczne dla ludzi i środowiska, wydajne oraz na tyle tanie, aby ich wykorzystanie okazało się opłacalne, cały czas jest w toku. Obecnie konsensus naukowców z grubsza przewiduje skupienie się na elektrowniach atomowych oraz OZE, z nadzieją, że w relatywnie bliskiej przyszłości uda się wyciągnąć energię także z fuzji jądrowych. Jednocześnie większość krajów na świecie daleka jest od tego ideału – przykładowo w Polsce wciąż około 60% prądu produkowane jest w uwalniających do atmosfery toksyczne odpady elektrowniach węglowych. Można więc bez szczególnej kontrowersji zaryzykować stwierdzenie, że oszczędzanie energii jest w naszym najlepiej pojętym interesie.
Ile w takim razie marnujemy jej na generowanie obrazków z papieżem w stroju superbohatera? Trudno oszacować, ale prawdopodobnie za dużo. Według raportu Electricity 2024 przygotowane przez International Energy Agency centra danych działające na potrzeby sztucznej inteligencji i kryptowalut zużywają około 460 terawatogodzin, co odpowiada około 2% całej produkowanej na świecie elektryczności. Czy to dużo? Cóż, nie aż tak, żeby panikować, ale warto pamiętać, że mówimy o w gruncie rzeczy jednej dość nowej technologii, która już na tym etapie rozwoju jest w stanie pochłonąć jedną pięćdziesiątą całej dostępnej ludzkości energii elektrycznej. Oczywiście spora część z tego służy jak najbardziej szczytnym celom: badaniom naukowym, wspomaganiu ważnych społecznie zawodów czy rozwojowi samej technologii. Nie da się jednoznacznie odpowiedzieć, jak dużo marnowane jest na tworzenie spamu w internecie, ale biorąc pod uwagę skalę zjawiska, z pewnością nie są to zaniedbywalne wartości.
Co więcej, takie boty potrafią – i coraz częściej będą – działać bez żadnego udziału człowieka. Już teraz prawdopodobnie dochodzi do sytuacji, w których programy rozmawiają same ze sobą albo odpowiadają sobie nawzajem na posty. Potencjałem na nieskończony flame jest chociażby wykorzystanie propagandy politycznej z użyciem sztucznej inteligencji. Spotkanie się botów zwolenników Donalda Tuska i Karola Nawrockiego prowadzić może do sytuacji, w której jedne będą próbowały zakrzyczeć drugie. Jeśli będzie to miało miejsce na jakimś niszowym portalu czy niewielkiej grupie na Facebooku, może nawet zdarzyć się tak, że większość tej „dyskusji” nigdy nie zostanie przeczytana przez jakąkolwiek ludzką istotę.
Istnieje jednak niebezpieczeństwo, że kiedyś przeczyta to... inna sztuczna inteligencja. Uczenie maszynowe to proces dość kosztowny, więc naturalną rzeczą jest szukanie oszczędności. Oszczędności, o których już dużo było w tym tekście – jeśli komputer może zrobić to samo co człowiek, taniej i szybciej będzie wykorzystać maszynę. Dlatego normą stało się, że nowsze generacje sztucznej inteligencji uczone są przez... te starsze. Pojawia się jednak coraz więcej doniesień, iż nie jest to dobra metoda. Trenowane w ten sposób programy wydają się głupsze od swoich poprzedników, ich odpowiedzi są mniej precyzyjne, bardziej ogólne, z większą tendencją do konfabulacji.
Proces uczenia modeli językowych to bowiem nic innego jak podawanie im do przetworzenia tysięcy stron tekstu, aby te mogły przeanalizować sposób budowania wyrazów, łączenia ich w zdania oraz dopasowywania do kontekstu. W efekcie uzyskujemy program zdolny generować wypowiedzi z grubsza podobne do tych, na których został wyszkolony. Przy obecnym rozwoju technologii maszyna nie jest jednak w stanie w żaden twórczy sposób ich przetworzyć czy dodać czegoś od siebie, więc wszystko, co możemy otrzymać, będzie odtwórcze i raczej niższej jakości. A zatem niezależnie od tego, czy wirtualny nauczyciel swoje lekcje generuje sam, czy pozyskuje je z zaśmieconego przez siebie internetu, kolejne iteracje modeli kształcą się na materiałach coraz słabszej jakości, a co za tym idzie – efekty szkolenia są coraz gorsze.
Być może jest to problem przejściowy – możliwe, że nowsze wersje sztucznych inteligencji będą mogły produkować teksty, grafiki i dźwięki nie gorsze niż autorstwa człowieka, a co za tym idzie, będą mogły szkolić przyszłe pokolenia równie dobrze jak ludzie. Dziś jednak zalew śmieciowej treści wygenerowanej przez komputery wydaje się problematyczny również dla samych maszyn.
Wreszcie – mnogość niskiej jakości materiałów tworzonych przez sztuczną inteligencję znacznie utrudnia komfortowe i produktywne korzystanie z internetu. Im bardziej ten jest bowiem martwy, tym więcej wysiłku trzeba włożyć w oddzielanie produkowanych przez żywe osoby ziaren od wirtualnie skleconych plew. W 2022 roku dziennikarz i pisarz Cory Doctorow we wpisie na blogu dowodził, że media elektroniczne mają tendencję do stawania się w toku swojego upowszechniania coraz mniej użytecznymi i coraz bardziej nastawionymi na łatwy zysk. Zarządzający serwisami społecznościowymi, które początkowo oferują relatywnie wartościowe usługi, wraz z przyrostem użytkowników coraz mniejszą wagę przywiązują do jakości swojego produktu, a coraz większą do jego monetyzacji – wprowadzania płatnych treści, elementów manipulacji mających skupić uwagę czytelnika czy socjotechnik nakłaniających do wydawania pieniędzy. Doctorow nazwał to zjawisko dość wulgarnie „gównowaceniem” (enshittification). I chociaż jego źródeł szukać należy na długo przed upowszechnieniem się sztucznej inteligencji, to właśnie ona jest w stanie przyspieszyć je wykładniczo. Wszystko, o czym pisałem w tym tekście, mieści się w definicji zaproponowanej przez Doctorowa. Czy to tworzenie farm lajków, czy to sianie propagandy, czy wreszcie prowadzony po kosztach marketing – to nic innego jak próby jak najwydajniejszego i jak najtańszego dorobienia się kosztem użytkowników.
Czy zatem jesteśmy bezbronni, a internet dawno już umarł? Jeszcze nie. Ale wiele wskazuje na to, że znajdujemy się w momencie historii, w którym ważą się jego losy. Czy pozostanie platformą wymiany informacji między żywymi osobami, czy może cmentarzyskiem wydanym na żer cyfrowym ghulom – to zależy od tego, jak społeczność internetowa poradzi sobie z zalewem spamu sztucznej inteligencji. A więc jak zwykle – głosujmy portfelami i dbajmy o jakość tego, co konsumujemy w sieci.
Wir i Blackwall
Idea internetu, który opanowany został przez nieprzyjazne ludziom sztuczne inteligencje, nie jest obca fantastyce naukowej. Pierwszym, co przychodzi do głowy, jest sytuacja w uniwersum Cyberpunka 2077 – tam stało się to w wyniku incydentu zwanego DataKrash. Od tego czasu od skrajnie niebezpiecznej sieci (pamiętajmy, że w tym uniwersum sztuczna inteligencja może łatwo doprowadzić do nieodwracalnych zmian osobowości czy wręcz śmieci nieostrożnego netrunnera) ludzkość odgrodzona jest tak zwanym Blackwallem.
Jednakże ciekawszą wizję zaproponował Peter Watts w swojej powieści Wir. Internet jest tam tak zaśmiecony, że aby wydobyć z niego jakąkolwiek sensowną informację i nie ryzykować infekcji swojego sprzętu przez szalejące w sieci wirusy, używa się mózgoserów. Są to biologiczne komputery ze specjalnie do tego celu wyhodowanej tkanki nerwowej. Mają one za zadanie filtrować dane napływające z wiru, jednak w toku optymalizacji tego procesu same nabierają pewnych uprzedzeń i pewne rodzaje informacji traktują priorytetowo. Brzmi niewinnie, ale stanowi rdzeń fabuły bardzo dobrej książki. Tak dobrej, że już drugi raz wspominam twórczość Wattsa.